
Рефераты по рекламе
Рефераты по физике
Рефераты по философии
Рефераты по финансам
Рефераты по химии
Рефераты по хозяйственному праву
Рефераты по экологическому праву
Рефераты по экономико-математическому моделированию
Рефераты по экономической географии
Рефераты по экономической теории
Рефераты по этике
Рефераты по юриспруденции
Рефераты по языковедению
Рефераты по юридическим наукам
Рефераты по истории
Рефераты по компьютерным наукам
Рефераты по медицинским наукам
Рефераты по финансовым наукам
Рефераты по управленческим наукам
Психология педагогика
Промышленность производство
Биология и химия
Языкознание филология
Издательское дело и полиграфия
Рефераты по краеведению и этнографии
Рефераты по религии и мифологии
Рефераты по медицине
Учебное пособие: Понятие многомерной случайной величины
Учебное пособие: Понятие многомерной случайной величины
Понятие многомерной случайной величины
Основные вопросы лекции: математическое ожидание случайной величины, свойства математического ожидания, дисперсия случайной величины, дисперсия суммы случайных величин, функция от случайных величин, математическое ожидание функций от случайных величин, коэффициент корреляции, моменты, корреляционный момент, виды сходимости последовательности случайных величин, неравенства Чебышева, график функции распределения для непрерывной случайной величины, различные формы закона больших чисел, теорема Чебышева, теорема Бернулли, теорема Маркова, центральная предельная теорема теории вероятностей, применение центральнойпредельной теоремы, обоснование роли нормального закона распределения, вывод приближенной формулы Лапласа.
Гипергеометрическое распределение
Выше мы рассмотрели способы вычисления вероятностей появления события ровно т раз в n независимых повторных испытаниях (по формулам Бернулли и Пуассона). Теперь познакомимся с вычислением вероятности появления события ровно т раз в n зависимых повторных испытаниях. Случайная величина, определяющая число успехов в n повторных зависимых испытаниях, подчиняется гипергеометрическому закону распределения.
Пример. В урне N шаров, среди которых К белых и (N–K) черных. Без возвращения извлечены n шаров. Определим вероятность того, что в выборке из n шаров окажется т белых (и соответственно n–m черных) шаров. Изобразим ситуацию на схеме:

Случайная величина, интересующая нас, X = т – число белых шаров в выборке объемом в n шаров. Число всех возможных случаев отбора n шаров из N равно числу сочетаний из N по n (CNn), а число случаев отбора т белых шаров из имеющихся К белых шаров (и значит, n–m черных шаров из N–K имеющихся черных) равно произведению CKmCN–Kn–m (отбор каждого из т белых шаров может сочетаться с отбором любого из n-т черных). Событие, вероятность которого мы хотим определить, состоит в том, что в выборке из n шаров окажется ровно т белых шаров. По формуле для вероятности события в классической модели вероятность получения в выборке т белых шаров (т.е. вероятность того, что случайная величина X примет значение т) равна
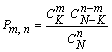 , (1)
, (1)
где CNn – общее число всех единственно возможных, равновозможных и несовместных исходов, CKmCN–Kn–m – число исходов, благоприятствующих интересующему нас событию.
Итак, вероятность появления интересующего нас события ровно т раз в n зависимых испытаниях вычисляется по формуле (1), которая задает значения гипергеометрического закона распределения для т = 0, 1, 2,…, n (табл. 1).
Таблица 1. Гипергеометрический закон распределения
| т | 0 | 1 | 2 | … | n |
| Р (X=m) |
CK0CN–k n/ CNn |
CK1CN–Kn–1/ CNn |
CK2CN–Kn–2/ CNn |
… |
CKmCN–K0/ CNn |
M(т) = nq, (2)
D(m) = nq (1–q) [1 – (n-1)/(N-1)], (3)
где q – доля единиц с интересующим нас признаком в совокупности N, т.е. q= K/N, а 1 – (n-1)/(N-1) называется поправкой для бесповторной выборки.
Производящая функция
Выше были рассмотрены способы определения вероятности Рn,mдля случаев, когда вероятность события А во всех n независимых испытаниях одна и та же. На практике приходится встречаться и с такими случаями, когда вероятность наступления события А от испытания к испытанию меняется.
Мультиномиальное распределение
Напомним, что в биномиальном эксперименте мы классифицируем исходы как успехи и неуспехи. Если обобщить ситуацию, то исходы можно классифицировать более чем по двум категориям. Предположим, есть k категорий исходов: «покупка товара А», «покупка товара В», «покупка товара К». Обозначим Х1 – число проданных единиц товара A, Х2 – число проданных единиц товара В,…., Хk – число проданных единиц товара К. Вероятностное распределение Х1, Х2,…, Хk в выборке объемом n есть мультиномиальное распределение с параметрами n и вероятностями р1, р2,…, рk, где рi – вероятность появления категории i (рi= 1 – qi), и они остаются неизменными от испытания к испытанию и испытания независимы.
Формула мультиноминального распределения имеет следующий вид:
P(Х1, Х2., Хk) = n!/(Х1! Х2!…∙Хk!)∙р1x1∙р2x2 ·…∙рkxk. (4)
Геометрическое распределение
Рассмотрим биномиальный эксперимент с обычными условиями. Пусть вместо вычисления числа успехов в независимых испытаниях случайная величина определяет число испытаний до первого успеха. Такая случайная величина распределена по закону геометрического распределения. Вероятности геометрического распределения вычисляются по формуле
P(m) = pqm–1, (5)
где т = 1, 2, 3,…; p и q – биномиальные параметры. Математическое ожидание геометрического распределения
M(m)= 1/p, (6)
а дисперсия σ2 = D(m) = q/p2. (7)
Например, число деталей, которые мы должны отобрать дотого, как найдем первую дефектную деталь, есть случайная величина, распределенная по геометрическому закону. В чем здесь смысл математического ожидания? Если доля дефектных деталей равна 0, 1, то вполне логично, что в среднем мы будем иметь выборки, состоящие из 10 деталей до тех пор, пока не встретим дефектную деталь.
Непрерывные случайные величины
Непрерывной случайной величиной называют случайную величину, которая может принимать любые значения на числовом интервале.
Примеры непрерывных случайных величин: возраст студентов, длина ступни ноги человека, масса детали и т.д. Это положение относится ко всем случайным величинам, измеряемым на непрерывной шкале, таким как меры веса, длины, времени, температуры, расстояния. Измерение может быть проведено с точностью до какого-нибудь десятичного знака, но случайная величина – теоретически непрерывная величина. В экономическом анализе находят широкое применение относительные величины, различные индексы экономического состояния, которые также вычисляются с определенной точностью, скажем, до двух знаков после запятой, хотя теоретически их значения – непрерывные случайные величины.
У непрерывной случайной величины возможные значения заполняют некоторый интервал (или сегмент) с конечными или бесконечными границами.
Закон распределения непрерывной случайной величины можно задать в виде интегральной функции распределения, являющейся наиболее общей формой задания закона распределения случайной величины, а также в виде дифференциальной функции (плотностираспределения вероятностей), которая используется для описания распределения вероятностей только непрерывной случайной величины.
Функция распределения (или интегральная функция) F(x) – универсальная форма задания закона распределения случайной величины. Для непрерывной случайной величины функция распределения также определяет вероятность того, что случайная величина X примет значение, меньшее фиксированного действительного числа х, т.е.
F(x) = F (X<x). (8)
При изменении х меняются вероятности Р (Х <x) = F(x). Поэтому F(x) и рассматривают как функцию переменной величины. Принято считать, что случайная величина X известна, если известна ее функция распределения F(x).
Теперь можно дать более точное определение непрерывной случайной величины: случайную величину называют непрерывной, если ее функция распределения есть непрерывная, кусочно-дифференцируемая функция с непрерывной производной.
Функция распределения есть неотрицательная функция, заключенная между 0 и 1, т.е. 0 ≤ F(x) ≤ 1.
Функция распределения есть
неубывающая функция, т.е. F(x2)≥ F(x1), если х2>
х1. Тогда P(x1 ≤ Х <х2) = P (Х <х2)
– P (Х <х1) = F(x2) –
– F(x1).
Так как любая вероятность есть число неотрицательное, то P(x1 ≤ Х <х2) ³ 0, а следовательно, F(x2) – F(x1) ≥ 0и F(x2) ≥ F(x1).
Следствие 1. Вероятность того, что случайная величина X примет значение, заключенное в интервале (α, β), равна приращению функции распределения на этом интервале, т.е.
P (α ≤ Х <β) = F(β) – F(α). (9)
Следствие 2. Вероятность того, что непрерывная случайная величина X примет одно определенное значение, равна нулю.
Р (Х = х1) = 0. (10)
Согласно сказанному, равенство нулю вероятности Р (Х = х1) не всегда означает, что событие Х = х1невозможно. Говоря о вероятности события Х = х1, априорно пытаются угадать, какое значение примет случайная величина в опыте.
Если х1лежит в области возможных значений непрерывной случайной величины X, то с некоторой уверенностью можно предсказать область, в которую случайная величина может попасть. В то же время невозможно хотя бы с малейшей степенью уверенности угадать, какое конкретное значение из бесконечного числа возможных примет непрерывная случайная величина.
Из перечисленных выше свойств F(х) может быть представлен график функции распределения (рис. 1).
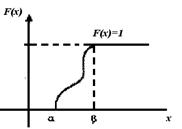
Рис. 1. График функции распределения непрерывной случайной величины
График функции распределения смешанной случайной величины – кусочно-непрерывная функция (рис. 2).

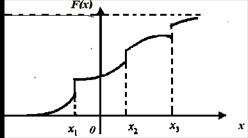
Рис. 2. График кусочно-непрерывной функции распределения
Плотностью распределения вероятностей непрерывной случайной величины X называется функция W(x), равная первой производной от функции распределения F(x),
W(x) =F ′(x), (1)
где W(x) – дифференциальная функция распределения. Дифференциальная функция применяется только для описания распределения вероятностей непрерывных случайных величин.
Вероятность того, что непрерывная случайная величина примет значение, принадлежащее интервалу (α, β), равна определенному интегралу от дифференциальной функции, взятому в пределах от α до β,
P (α <X< β) = 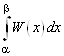 . (2)
. (2)
Используя соотношения (2) и
(1), получим P (α ≤ X< β) = P (α <<X<< β)
= 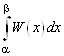 .
.
Геометрически этот результат равен площади криволинейной трапеции, ограниченной осью ОХ, кривой распределения W(x) и прямымих = α, х = β.
Зная плотность распределения W(x), можно найти функцию распределения F(x) по формуле
F(x) = 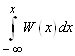 . (3)
. (3)
В самом деле, так как
неравенство X <х можно записать в виде двойного неравенства – ∞ <X <х,
то F(x) = P (– ∞ <X < х) =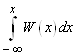 (рис. 3).
(рис. 3).
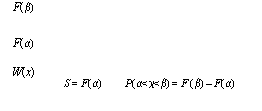
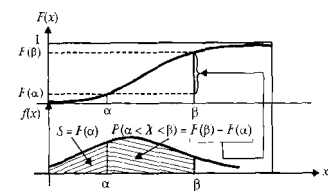
Рис. 3. Связь функции распределения с плотностью распределения вероятностей
Таким образом, для полной характеристики непрерывной случайной величины достаточно задать функцию распределения или плотность ее вероятности.
1. Дифференциальная функция – неотрицательная функция:
W(x) ≥ 0. (4)
Это следует из того, что F(x) – неубывающая функция, а значит, ее производная неотрицательна.
2. Несобственный интеграл от дифференциальной функции в пределах от – ∞ до + ∞ равен 1
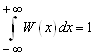 . (5)
. (5)
Очевидно, что этот интеграл выражает вероятность достоверного события – ∞ <Х + ∞.
Математическим ожиданием непрерывной случайной величины называется несобственный интеграл вида
М(Х) =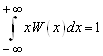 . (6)
. (6)
Дисперсией непрерывной случайной величины называется несобственный интеграл вида
D(x) = σ2 =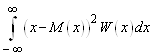 . (7)
. (7)
Средним квадратическим отклонением непрерывной случайной величины называется квадратный корень из дисперсии
σ = ![]() . (8)
. (8)
Для числовых характеристик непрерывных случайных величин справедливы те же свойства, что и для дискретных. В частности, для дисперсии непрерывной случайной величины справедлива формула
D(X)=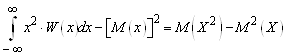 . (9)
. (9)
Начальным моментом k-го порядка(mk) случайной величины X называется математическое ожидание ее k-й степени:
для дискретной случайной
величиныmk=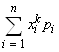 ;
;
для непрерывной случайной
величиныmk= 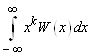 . (10)
. (10)
Центральным моментом k-го порядка (μк) случайной величины X называют математическое ожидание k-й степени отклонения случайной величины X от ее математического ожидания:
для дискретной случайной
величиныμk= ;
;
для непрерывной случайной величины
μk=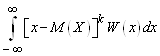 .
(10)
.
(10)
Заметим, что начальный момент первого порядка m1представляет собой математическое ожидание случайной величины, а центральный момент второго порядка μ2 – дисперсию случайной величины.
Центральный момент третьего порядка применяется для характеристики скошенности или асимметрии распределения (коэффициентасимметрии):
β1 = μ3/σ3. (12)
Для симметричных распределений β1 = 0. Центральный момент 4-го порядка применяется для характеристики крутости (эксцесса) распределения (неприведенный коэффициент эксцесса):
β2 = μ4/σ4. (13)
Часто в практических ситуациях используют квадрат коэффициента асимметрии и приведенный коэффициент эксцесса.
γ1 = β12=μ23/σ6; γ2 = β2–3 = μ4/σ4–3.
Величина хр, определяемая равенством F(xp) = Р (Х <хр), называется квантилью уровня p. Квантиль х0,5 называется медианой. Значение х, при котором W(x) принимает максимальное значение, называется модой.
Нормальное распределение
Наиболее важным распределением непрерывных случайных величин является нормальное распределение. Множество явлений в практической жизни можно описать с помощью модели нормального распределения, например распределение высоты деревьев, площадей садовых участков, массы людей, дневной температуры и т.д. Нормальное распределение используется и для решения многих проблем в экономической жизни. Например, распределение числа дневных продаж в магазине, числа посетителей универмага в неделю, числа работников в некоторой отрасли, объемов выпуска продукции на предприятии и т.д.
Нормальное распределение находит широкое применение и для аппроксимации распределения дискретных случайных величин. Так, например, доходы от определенных видов рискованного бизнеса приблизительно подчиняются нормальному распределению.
Нормальное распределение иногда называют законом ошибок. Например, отклонения в размерах деталей от установленного объясняются многими причинами, каждая из которых влияет на размер детали, так что отклонение, которое фактически регистрируется при измерениях, является суммой большого числа отклонений (ошибок).
Нормальная случайная величина имеет плотность распределения, определяемую формулой
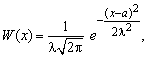 (1)
(1)
где – ∞ < x < + ∞, а = М(Х), λ = σ(Х).
Основные свойства W(x):
а) функция W(x) существует при любых действительных значениях х и принимает только положительные значения. Следовательно, нормальная кривая распределения расположена выше оси абсцисс;
б) при неограниченном возрастании х по абсолютной величине W(x) стремится к нулю, значит, ось абсцисс служит горизонтальной асимптотой кривой нормального распределения;
в) максимальное значение функция W(x) принимает в точке, соответствующей математическому ожиданию случайнойвеличины х.
Действительно, приравнивая первую производную от W(x) к нулю, т.е.
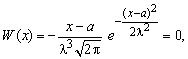
убеждаемся в том, что W(x)' = 0 при х = a; W'(х)> 0 при х < а; W'(x)<< 0 при х> а.
Следовательно, функция W(х) принимает максимальное значение в точке х = а;
г) кривая нормального распределения симметрична относительно прямой х = а, поскольку разность x – а входит в формулу (1) в квадрате;
д) кривая нормального
распределения имеет две точки перегиба, симметрично расположенные относительно
прямой х = а, с абсциссами точек перегиба а – λ и а + λ и ординатами ![]() .
.
Формула (6.1) содержит два параметра: математическое ожидание а = М(Х) и стандартное отклонение λ = σ(X). Следовательно, существует бесконечно много нормально распределенных случайных величин, у которых разные M(Х) и σ(X). Графики их плотностей имеют одинаковую форму – симметричную, колоколообразную. Если М(Х) и σ(X) известны, то из семейства нормальных случайных величин выделяем конкретную нормальную случайную величину с определенной плотностью.
Математическое ожидание а – это величина, которая характеризует положение кривой распределения на оси абсцисс (рис. 1). Изменение параметра а при неизменном λ приводит к перемещению оси симметрии (х = а) вдоль оси абсцисс и, следовательно, к соответствующему перемещению кривой распределения. М(Х) = а иногда называют центрам распределения или параметром сдвига. При х = М(Х) = = а плотность распределения вероятности наибольшая, а вследствие симметрии плотности а = Мо= Ме, и площадь, расположенная под кривой, делится пополам осью симметрии. Здесь Мо – мода распределения, Ме – медиана.
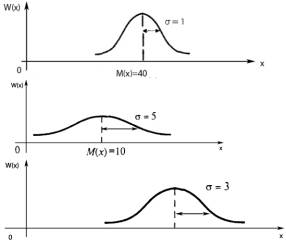
Рис. 1. Кривые плотности нормального распределения с различными а и λ
Изменение среднего квадратического отклонения при фиксированном значении математического ожидания приводит к изменению формы кривой распределения. С уменьшением λ вершина кривой распределения будет подниматься, кривая будет более «островершинной» (вытянутой вдоль оси симметрии). С увеличением λ кривая распределения менее островершинная и более растянута вдоль оси абсцисс. Одновременное изменение параметров a и λ приведет к изменениюи формы, и положения кривой нормального распределения.
Условимся о форме записи случайных величин. Например, запись X~а (X; М(Х), σ2) означает: случайная величина X подчиняется закону распределения а с математическим ожиданием М(Х) и средним квадратическим отклонением σ, либо дисперсией σ2. Это общая форма записи случайной величины, распределенной по закону а. Если речь идет о биномиальном законе, то будем обозначать В; о нормальном – N и т.д.
Итак, если мы имеем дело со случайной величиной, подчиняющейся нормальному закону распределения, с математическим ожиданием а = 5,7 и λ = 2, то запись будет X~N (X; 5,7; 22).λ2записывается как 22, а не 4.
Стандартное (нормированное) нормальное распределение
Если вформуле (1) а = 0; λ = 1, то
φ(z) = 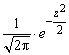 . (2)
. (2)
При а = 0 и λ = 1
нормальное распределение называют стандартным (нормированным) нормальным
распределением (рис. 2), а кривую ![]() –
нормированной.
–
нормированной.
|
Свойства функции φ(z):
а) функция φ(z) – четная, т.е.
φ(z) = φ(– z);
б) с увеличением z по абсолютной величине φ(z) монотонно убывает и при z → ∞ имеет пределом нуль;
в) при z = 4 φ(z) = 0,0001, при z = 5 φ(z) = 0,0000015, поэтому при |z | > 5 можно считать, что φ(z) = 0. В связи с этим таблицы ограничиваются значениями функции φ(z) для аргументов z = 4 или z = 5;
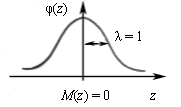
Рис. 2. График кривой стандартного нормального распределения
г) максимальное значение функция φ(z) принимает при z = 0.
Сравнивая (1) и (2), можно сделать вывод: плотность случайной величины, распределенной по нормальному закону, можно записать как:
W(x) =![]() . (3)
. (3)
Любая нормально распределенная случайная величина может быть преобразована в стандартную (нормированную) нормально распределенную случайную величину.
Итак, переход X в Z достигается преобразованием:
Z = (x – a)/λ. (4)
При помощи формулы (6.4) можно преобразовать любую нормально распределенную случайную величину X в стандартную нормально распределенную случайную величину Z. Обратное преобразование стандартной нормальной случайной величины Z в Х~N (Х; a; λ2) можно осуществить по формуле:
X = a+Z∙λ. (5)
Вероятность попадания в заданный интервал нормально распределенной случайной величины.
Мы знаем, что если случайная величина задана плотностью распределения W(x), то вероятность того, что X примет значение, принадлежащее интервалу (α, b), определяется из выражения
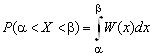 .
.
Если случайная величина X ~ N (a; σ2), то
P (a<X<b) = 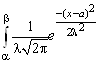 dx.
dx.
Для того чтобы можно было
пользоваться готовыми таблицами для вычисления вероятностей, преобразуем X в
Z и найдем новые пределы интегрирования. Если х = a, то z=(a–а)/λ, если х=b, то z= (b – а)/λ. Тогда P (a< X<b) = 1/(λ![]() ),
),
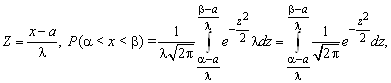
где x = a + zλ; dx = λdz.
Интеграл вида  dt называется интегралом
вероятностей, или функцией Лапласа. Его обычно обозначают символом F0(z):
dt называется интегралом
вероятностей, или функцией Лапласа. Его обычно обозначают символом F0(z):
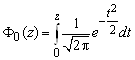 (6)
(6)
Интеграл Лапласа в общем виде не берется. Его можно вычислить одним из способов приближенного вычисления интегралов. Эта функция табулирована. Пользуясь функцией Лапласа, окончательно получаем:
P (a<X <b) = ![]() .
(7)
.
(7)
Формула (7) называется интегральной теоремой Лапласа.
Свойства F0(z):
а) функция F0(z) является нечетной функцией; т.е. F0(–z)= –F0(z);
б) при z = 0 функция
Лапласа равна нулю 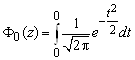 =0;
=0;
в) при z®+∞F0(z)®0,5; при z® –∞ F0(z)® –0,5.
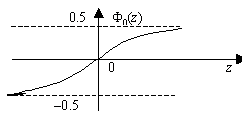
Рис. 4. График интегральной функции Лапласа–Гаусса
Ф0(4) = 0,499997, Ф0(–4) = –0,499997. Значит, при úzú> 4 можно считать, что Ф0(4) » ± 0,5. Итак, все возможные значения интегральной функции Лапласа принадлежат интервалу (–0,5; +0,5).
Итак, функция распределения случайной величины, подчиняющейся нормальному закону распределения, представленная через функцию Лапласа,
F(x) = 0,5+Фо[(x – a)/λ]. (8)
Рассмотрим ряд примеров на вычисление вероятностей при помощи таблиц стандартного нормального распределения и нахождение значений Z по заданной вероятности.
Правило «трех сигм»
Если обозначить (x–a)/σ = Z, Δ = (x – a) = σZ, то
P (|X – a| < z) = 2Ф0(z), (9)
где 2Ф0(z) – вероятность того, что отклонение случайной величины от ее математического ожидания М(Х)= а по абсолютной величине будет меньше z сигм. Придадим z значения 1; 2; 3. Пользуясь формулой (9) и таблицей интеграла вероятностей, вычислим вероятность того, что отклонение по абсолютной величине будет меньше σ, 2σ и Зσ:
при z =1, Δ = σ и P (|X–a|<σ) = 2Ф0(1) = 0,6826;
при z =1, Δ =2σ и P (|X–a|<2σ) = 2Ф0(2) = 0,9544
при z =1, Δ =3σ и P (|X–a|< 3σ) = 2Ф0(3) = 0,9973.
Приведенные результаты вычислений представлены на рис. 5.
Вероятность того, что случайная величина попадет в интервал (а – σ; а + σ), равна 0,6826. Геометрически эту вероятность можно представить заштрихованной частью площади под кривой, изображенной на рис. 8. Вероятность того, что случайная величина попадет в интервал (а – 2σ; а +2σ), равна 0,9544. Вероятность того, что случайная величина попадет в интервал (а – 3σ; а +3), равна 0,9973 (на рис. 8 эта вероятность представлена почти всей площадью, заключенной между кривой распределения и осью абсцисс).

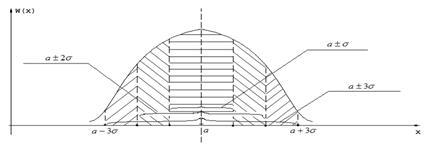
Рис. 5. К правилу «трех сигм»
Следовательно, вероятность того, что отклонение случайной величины от своего математического ожидания по абсолютной величине превысит утроенное среднее квадратическое отклонение, очень мала и равна 0,0027. Такие события считаются практически невозможными.
В этом и состоит правило «трех сигм»: если случайная величина распределена по нормальному закону, то ее отклонение от математического ожидания практически не превышает±3σ.
Понятие о теоремах, относящихся к группе «центральной предельной теоремы»
В теоремах этой группы выясняются условия, при которых возникает нормальное распределение. Общим для этих теорем является следующее обстоятельство: закон распределения суммы достаточно большого числа независимых случайных величин при некоторых условиях неограниченно приближается к нормальному. Познакомимся с содержанием (без доказательства) с одной из таких теорем.
Центральная предельная теорема для одинаково распределенных слагаемых (П. Леви). Если независимые случайные величины Х1, Х2,… Хn, имеют один и тот же закон распределения с математическим ожиданием а и дисперсией σ2, то при неограниченном увеличении n закон распределения суммы Х1 + Х2 + … + Хn неограниченно приближается к нормальному.
Теорема Ляпунова. Если случайная величина Y представляет собой сумму большого числа независимых случайных величин Y1, Y2,… Yn, влияние каждой из которых на всю сумму равномерно мало, то величина Y имеет распределение, близкое к нормальному, и тем ближе, чем больше п.
При этом ценно то, что законы распределения суммируемых случайных величин могут быть любыми, заранее не известными исследователю. Практически данной теоремой можно пользоваться и тогда, когда речь идет о сумме сравнительно небольшого числа случайных величин. Опыт показывает, что при числе слагаемых около 10 закон распределения суммы близок к нормальному.
Теорема Ляпунова имеет важное практическое значение, поскольку многие случайные величины можно рассматривать как сумму отдельных независимых слагаемых. Например: ошибки различных измерений; отклонения размеров деталей, изготовляемых при неизменном технологическом режиме; распределение числа продаж некоторого товара, объемов прибыли от реализации однородного товара различными производителями; валютные курсы; рост, вес животных и растений данного вида; отклонение точки падения снаряда от цели и т.д. могут рассматриваться как суммарный результат большого числа слагаемых и потому приближенно следовать нормальному закону распределения.
Показательное (экспоненциальное) распределение
Экспоненциальное (показательное) распределение тесно связано с распределением Пуассона, которое используется для вычисления вероятности появления события в некоторый период времени. Распределение Пуассона – это распределение числа появления событий в заданный интервал времени длиной t. Единственный параметр распределения Пуассона λ характеризует интенсивность процесса, т.е. с его помощью мы можем вычислить среднее число появления события.
Закон равномерного распределения (равномерной плотности)
Если возможные значения непрерывной случайной величины принадлежат определенному интервалу, а плотность ее распределения на этом интервале остается постоянной, то говорят, что данная случайная величина распределена по закону равномерной плотности.
В равномерном распределении вероятность того, что случайная величина будет принимать значения внутри заданного интервала, пропорциональна длине этого интервала.
Пусть непрерывная случайная величина X распределена на интервале (α, β) с равномерной плотностью. Ее плотность W(х) на этом участке постоянна и равна C. Вне этого интервала она равна нулю, так как случайная величина X за пределами интервала (α, β) значений не имеет (рис. 6).
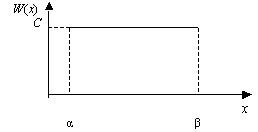
Рис. 6. Общий вид графика функции плотности равномерного распределения
Найдем значение постоянной С. Площадь, ограниченная кривой распределения и осью абсцисс, должна быть равна единице, т.е. С (β – α) = 1. Следовательно, С = 1/(β – α) и плотность для равномерного распределения можно записать:
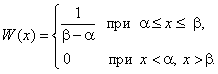 (10) Функция распределения
(10) Функция распределения
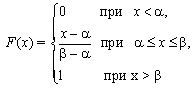 (11)
(11)
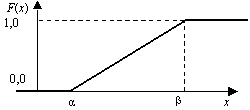
Рис. 7. График функции распределения для случайной величины, распределенной по закону равномерной плотности
Математическое ожидание непрерывной равномерно распределенной случайной величины
М(Х)= (α + β)/2, (12)
дисперсия D(x) = (β –α)2/12, (13)
среднеквадратичное отклонение
s(x)
= ![]() = (β – α) / (2
= (β – α) / (2![]() ). (14)
). (14)
Для непрерывной равномерно распределенной случайной величины X, заданной на интервале
(a<X<b), P (a<X<b) = (b–a)/(β – α), (15)
если ![]() .
.
Литература: [2], [4], [5].
Литература
1. Высшая математика для экономистов: Учебник для вузов / Под ред. Н.Ш. Кремера. – М.: ЮНИТИ, 2003.
2.Е.С. Кочетков, С.О. Смерчинская Теория вероятностей в задачах и упражнениях / М. ИНФРА-М 2005.
3. Высшая математика для экономистов: Практикум / Под ред. Н.Ш. Кремера. – М.: ЮНИТИ, 2004.Ч1, 2
4. Гмурман В.Е. Руководство к решению задач по теории вероятностей и математической статистике. М., Высшая школа, 1977
5. Гмурман В.Е. Теория вероятностей и математическая статистика. М., Высшая школа, 1977
6. М.С. Красс Математика для экономических специальностей: Учебник/ М. ИНФРА-М 1998.
7. Выгодский М.Я. Справочник по высшей математике. – М., 2000.
8. Берман Г.Н. Сборник задач по курсу математического анализа. – М.: Наука, 1971.
9.А.К. Казашев Сборник задач по высшей математике для экономистов – Алматы-2002 г.
10. Пискунов Н.С. Дифференциальное и интегральное исчисление. – М.: Наука, 1985, Т1,2.
11.П.Е. Данко, А.Г. Попов, Т.Я. Кожевников Высшая математика в упражнениях и задачах/ М. ОНИКС-2005.
12.И.А. Зайцев Высшая математика/ М. Высшая школа-1991 г.
13. Головина Л.И. Линейная алгебра и некоторые ее приложения. – М.: Наука, 1985.
14. Замков О.О., Толстопятенко А.В., Черемных Ю.Н. Математические методы анализа экономики. – М.: ДИС, 1997.
15. Карасев А.И., Аксютина З.М., Савельева Т.И. Курс высшей математики для экономических вузов. – М.: Высшая школа, 1982 – Ч 1, 2.
16. Колесников А.Н. Краткий курс математики для экономистов. – М.: Инфра-М, 1997.
17.В.С. Шипацев Задачник по высшей математике-М. Высшая школа, 2005 г.